Written by: Michael Mozer, Scientific Advisor at AnswerOn and Professor at the University of Colorado
Background on Research Publications
Advances in all scientific fields are communicated in academic research publications. In some fields, the publications of choice are top tier journals like Science or Nature. To publish in a peer-reviewed journal, one submits a manuscript, the editor decides if the topic and content are suitable for the journal, and if so, the editor sends the manuscript out to experts for review. The expert reviews vary from a few paragraphs to a dozen pages. The editor then decides whether the manuscript should be published as is or with minor revisions, revised significantly and resubmitted, or rejected.
A more rapid road to publication is via an academic conference. In machine learning, top conferences include Neural Information Processing Systems (NIPS), which I mentioned in my previous post, the International Conference on Machine Learning (ICML), and Uncertainty in AI (UAI). Due to the long lag between submission and publication in a journal, conferences in computer science have begun to serve as an rapid alternative route to disseminating results. Conference papers are typically shorter than journal articles, but still undergo stringent scrutiny by at least three reviewers, the authors can respond to the reviewer reports, and then the program committee makes a final decision. Acceptance rates at conferences can be quite low, below 20%. At NIPS and ICML, most research is presented on posterboards in a session where the authors of the work stand by their posters to describe the work to interested parties. A relatively small number of papers are featured as oral presentations in a general session that can have an audience of thousands.
Although reviewers and editors evaluate the contribution of a research article, it’s often not possible at the time of publication to know the impact the work will have. The ultimate determination is made by whether its ideas are leveraged by others to further advance the field. Because researchers cite earlier work that that has influenced their thinking, the number of citations an article receives—whether a journal or conference paper—is a sensible proxy for the article’s value to the field. Sites like Google Scholar provide citation statistics and links from citing to cited articles.
Churn Prediction and NIPS
In 1999, Eric Johnson, the CEO of AnswerOn, and I, along with several colleagues, submitted an article on churn prediction in the telecommunication industry to NIPS. The article was one of select few (about 5%) accepted for oral presentation. We described experiments on what was at the time a very large real-world data set, with about 100,000 records. It was also, as far as I remember, the first research involving machine learning and churn prediction and remediation. We compared the performance of different types of models, and discussed how features could be crafted to improve prediction. The work is not remarkable by today’s standards, but it apparently stood out in the pool of submissions to the conference at the time. The following year, we published an expanded version of the article with more extensive experiments in a journal, IEEE Transactions on Neural Networks.
I recently looked up citation counts for these two articles. Here’s a graph showing the cumulative number of citations over time.
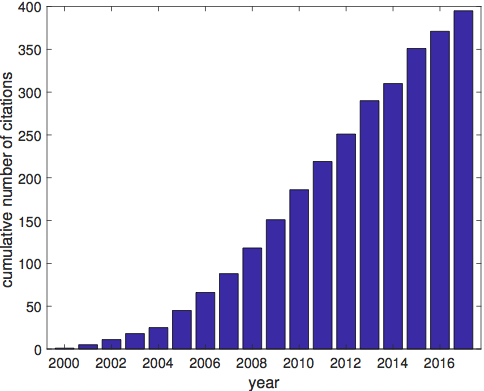
The work continues to be regularly cited for its innovation in tackling the churn problem with neural networks. Our results are still considered state-of-the-art, and provide a useful reference for others tackling their own data sets. Of course, each churn data set is different, but it’s important to have documentation of how challenging churn prediction can be. In domains such as object recognition, state of the art requires near perfect discrimination among objects. In a domain like stock index prediction, being slightly above chance is extremely valuable. In terms of difficulty, churn prediction turns out to lie closer to stock index prediction than object recognition, and our paper showed that even weak indicators of churn could be leveraged to achieve significant savings.
As neural networks and deep learning regained popularity in the 2010’s, the pace of research has accelerated, and a new venue, called arXiv, has emerged for announcing ideas and results. arXiv.org is an open-access site hosted by Cornell University that allows anyone with legitimate credentials to post article drafts without formal review. Authors can update their drafts such that one can always find the latest version—as well as earlier versions—on the site. As one would expect, the lack of formal review allows for the posting of half-baked work, but the forum has become a legitimate means of disseminating results. Papers appearing on arXiv can be cited dozens of times before they are even submitted to conferences. arXiv has contributed to accelerating the pace of many fields, at the cost of folks like myself feeling overwhelmed by the amount of material posted each day.
In the old days, conference and journals were published in hard copy form. Now, nearly everyone accesses articles electronically. Because there is little difference in grabbing a paper from arXiv or grabbing the same paper from a conference or journal web site, I imagine that at some point there will be convergence and possibly the emergence of a unified publishing forum.
If you wish to explore modern machine learning research, I recommend starting with the NIPS proceedings, the ICML proceedings, or arXiv.
Citations
Mozer, M. C., Wolniewicz, R., Grimes, D. B., Johnson, E., & Kaushansky, H. (1999). Churn reduction in the wireless industry. In S. A. Solla, T. K. Leen & K.-R. Mueller (Eds.), Advances in Neural Information Processing Systems 12 (pp. 935-941). Cambridge, MA: MIT Press.
Mozer, M. C., Wolniewicz, R., Grimes, D., Johnson, E., & Kaushansky, H. (2000). Maximizing revenue by predicting and addressing customer dissatisfaction. IEEE Transactions on Neural Networks, 11, 690-696.

